现在有一组在一段时间内医院某科室中的病人病历数据,现希望对该数据进行可视化,以观察来该科室看病的病人是否更多(或更少)地被确诊出某些特定的疾病。
对问题的转化和解决方案的讨论
最直观的思路就是将该病历数据转化为每一种病和其对应被诊断出该病的病人数目的数据然后作散点图,横坐标为特定疾病,纵坐标为的该病的人的数目。但有如下几个问题:
- 如果选择可视化的是病和其对应被诊断出该病的病人数目的数据,那么如何科学选定阈值?
- 由于这是一个整数型的离散数据,会有大量的数据点重叠(比如会有大量的病只有一两个人得),而为每一种病都单独留出一个横坐标的位置,又不太现实,如何处理?
在查阅了各种可视化方案中,最后敲定了一种结合蜂群图(beeswarm plot)和曼哈顿散点图(manhattan plot)的方案作为输出结果。
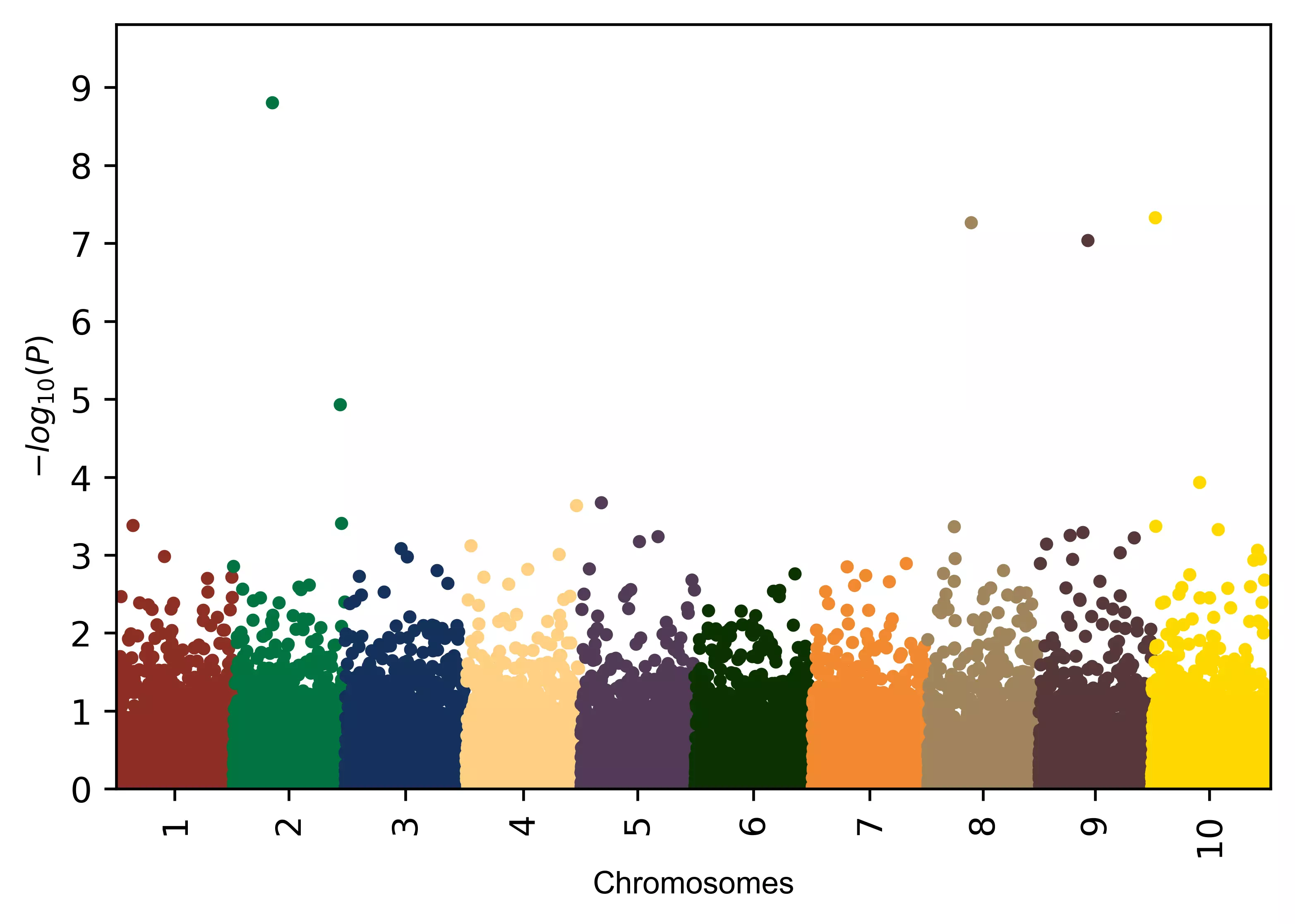
曼哈顿图(如上图)本质上是一个散点图,用于显示大量非零大范围波动数值,最早应用于全基因组关联分析(GWAS)研究展示高度相关位点。它得名源于样式与曼哈顿天际线相似(如下图)。一般在GWAS研究中所作的曼哈顿图的X轴为染色体编号,Y轴为相关统计显著性的p值,以10为底进行负对数变换。这样高显著性的基因就会在最上层。

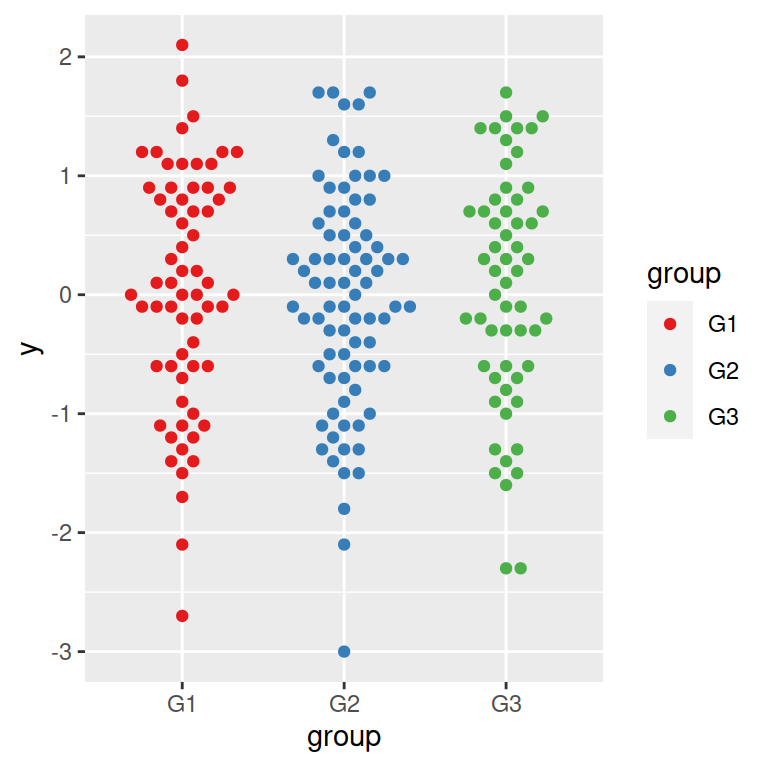
而蜂窝图(如下图)本质上也是一种散点图,它的优势在于可以无重叠地呈现所有数据信息。
选择这个方案的理由是现有疾病数据都被Phecode统一编码,且使用的编码系统分级比较合理(相对扁平,且每一类所包含的等级数量都相对一致),编码被分成的大类的类数也比较合适(10类)。这样就可以将Phecode的将疾病分成的大类编号作为X轴。但由于没有可以用来对照的数据(比如在整个医院或者社会中该病的发病情况),无法进行假设检验,所以最后还是敲定使用被诊断出该病的病人的绝对数量作为Y轴,并使用病人总数的65%(向下取整)作为作为标注的阈值。
实现细节
1 | import numpy as np |
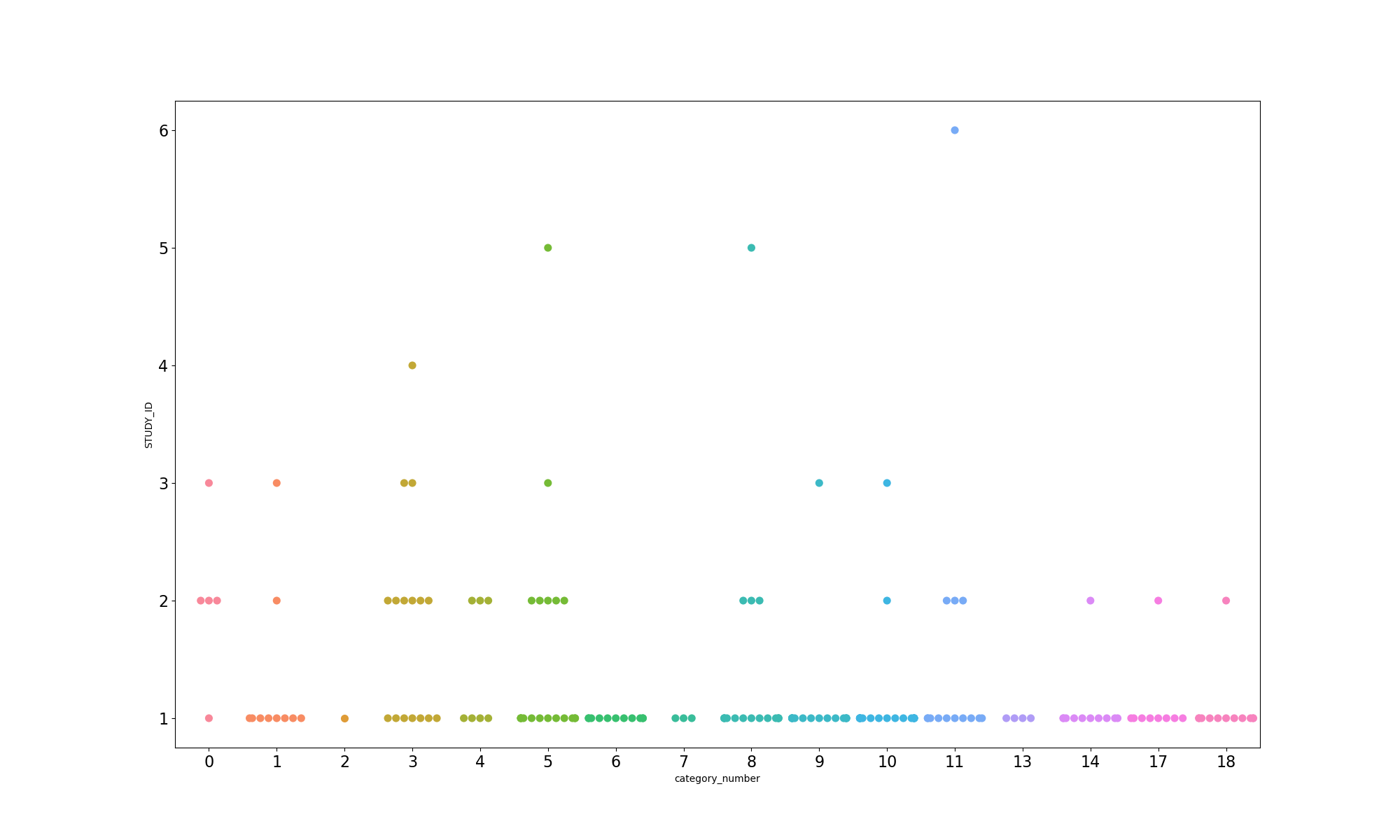
但接下来遇到一个问题,由于重叠的点数量过多,使用sns.swarmplot指令无法完整显示所有的数据点(如下图),而这个绘图命令无法控制点自动换行,如何处理?
最后想到的办法是将所有的点进行一次限制上下限的正态变换。根据正态分布的概率密度分布函数可知,这个变换可以保证有较多的数据点落在原值上,且小部分的点会等概率地分布在原值上下不远的位置。同时这个更接近原值的值和远离原值的值的比例可以通过控制标准差的大小来控制。其实最理想的情况是当重叠的数据点少于一定数量的时候可以直接不进行变换,但因为懒就没写。
这一步的成品如下图,很明显,在同样大小的画布下,出现的数据点更多了。
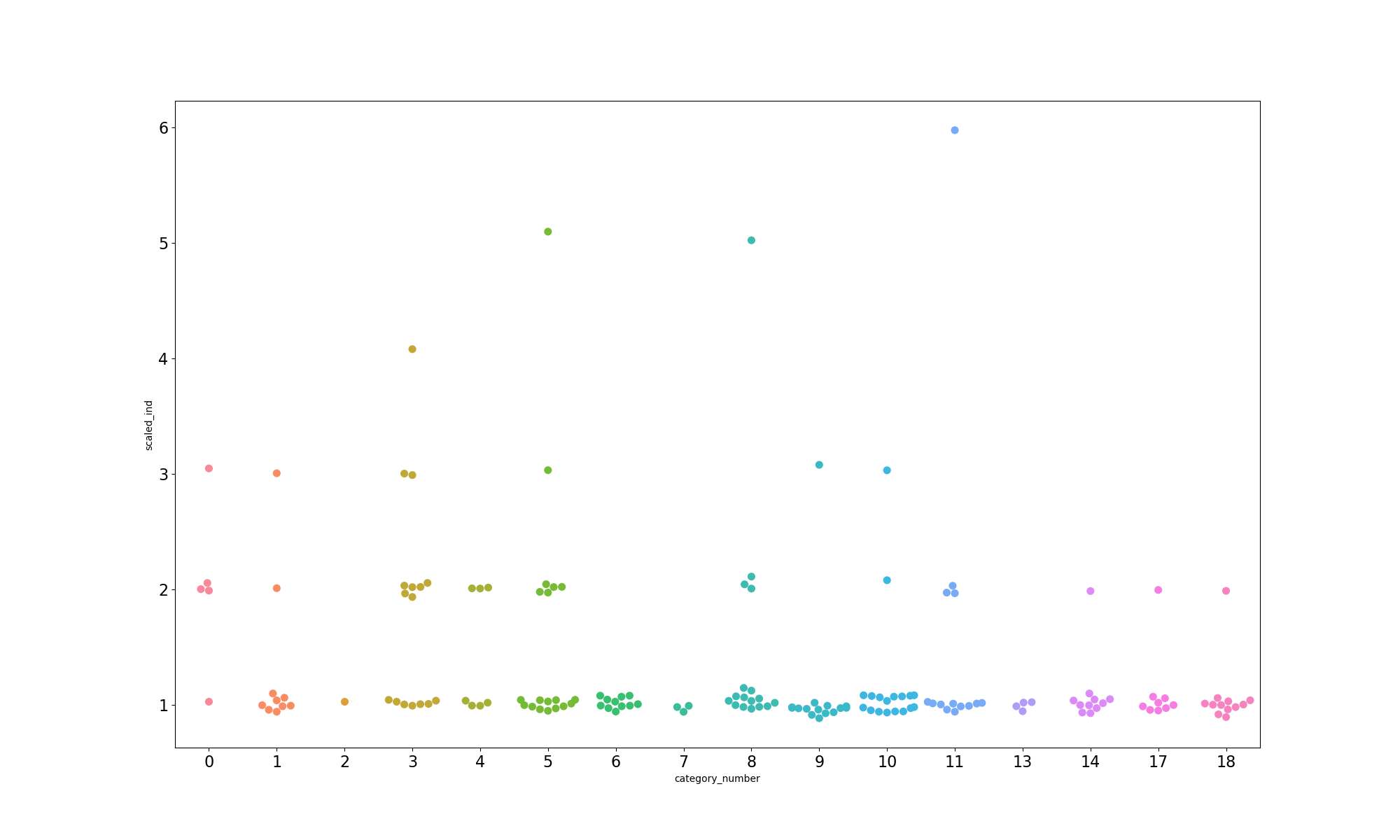
将对应的病人数目进行正态变换
1 | # np.clip函数可以同时更改输入的最大值和最小值,这里我们选取原值的上下0.4作为上下限,这样画出来的效果比较好 |
绘制曼哈顿图的主体并上色
本来绘图函数是可以自己选择上色的,但为了增加对比效果我这里选择了四种更容易分辨的颜色。因此需要对这10类数据点用这四种颜色进行循环上色。这里需要用到sns.set_palette和sns.color_palette两个函数。首先先创建一个包含所有想要绘制的颜色(以16进制RGB颜色编码表示)的列表,列表内颜色的顺序是单次循环上色的顺序。然后将其通过复制延长至要上色的数据类别的数量,并通过sns.color_palette将其转换成seaborn可以识别的色号,最后再通过sns.set_palette将接下来要绘图的色盘更改至输入的色号集合即可。
1 | color_item = ['#D55E00','#009E73','#0072B2', '#F0E442'] |
绘制注释
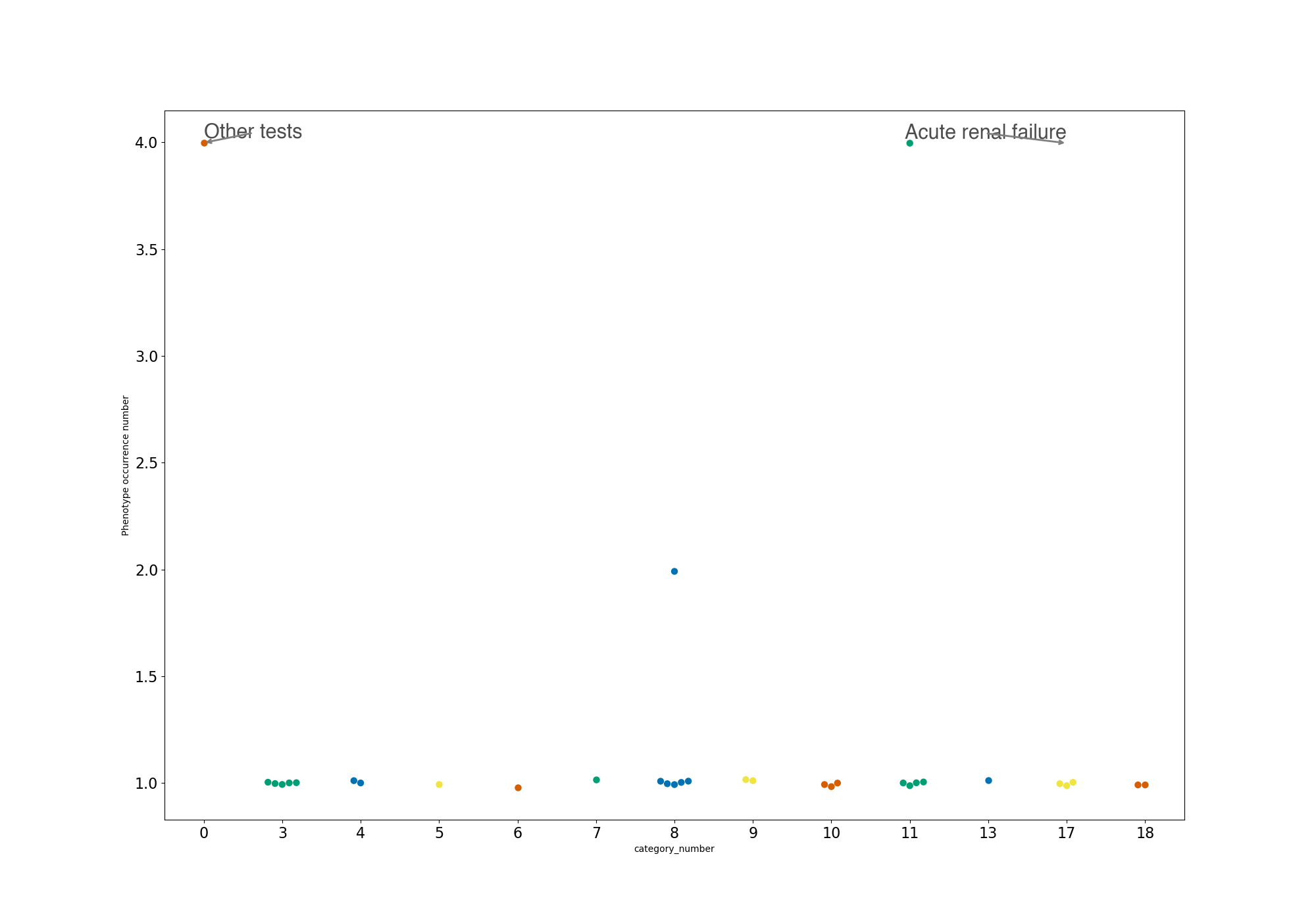
接下来要给想要重点观察的疾病制作注释。基本的函数是ax.annotate,需要输入待注释的文字以及注释的位置,对于二维散点图自然就是一个形如(pos_x, pos_y)的数组。但是我们发现由于这里横坐标中的类别也是以数字形式表示的,因此传入类别编号无法让作图函数识别成正确的对应位置(如下图,右上角的箭头很明显指歪了),因此此处需要传入注释点的绝对位置才行。另外如果待注释的散点较多且分布较密的话也很容易重叠,所以这里使用了一个叫做adjustText的包,它可以让注释位置分布更合理。在使用adjustText的情况下注释方式大体一致,只是需要把待注释的文字转成一个ax.text类的对象,其中包含注释的位置和待注释的文字即可。
1 | from adjustText import adjust_text |
最后的成品如下: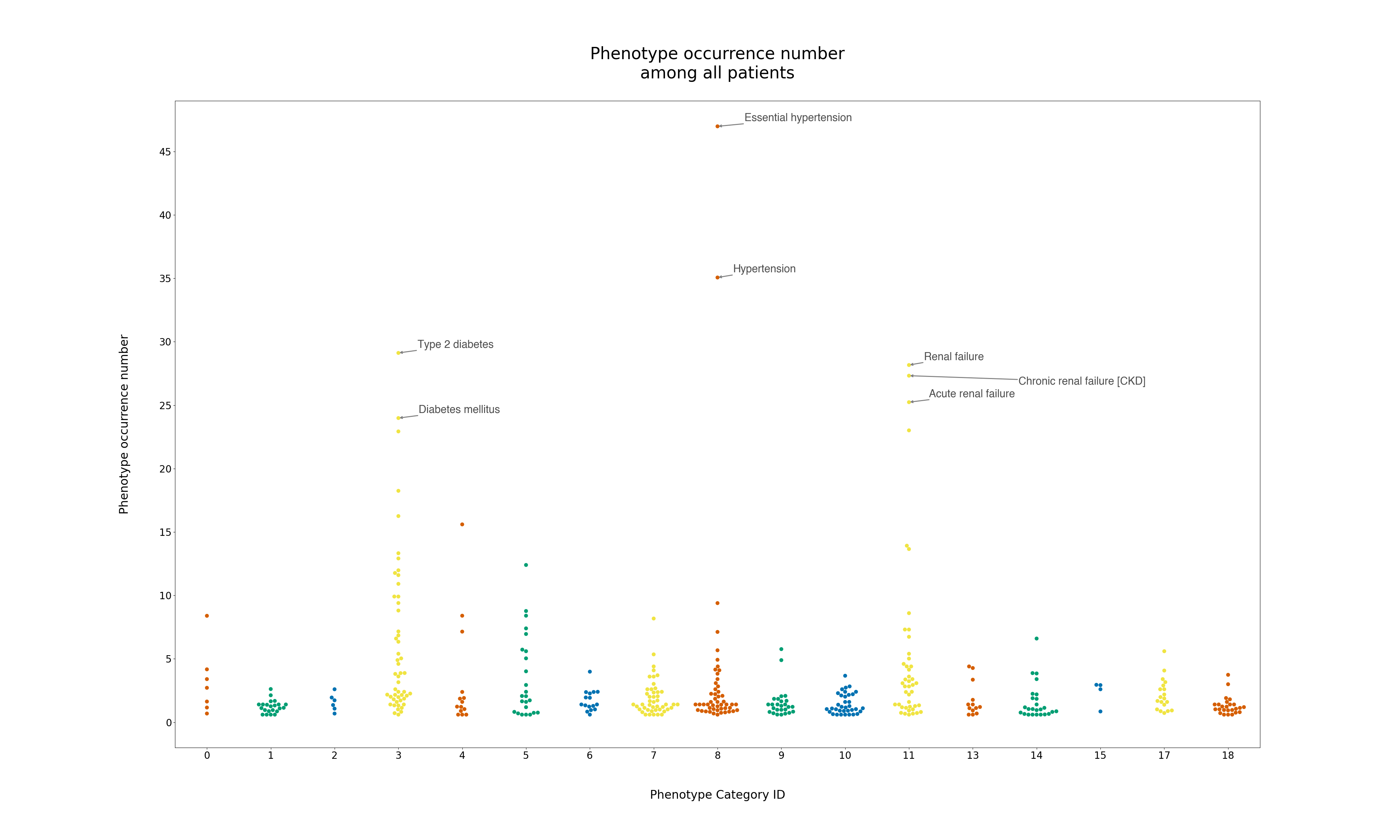
小结
本博文解决了如下问题:
- 如何使用一个简单的方式把大量相同的值转换成类似蜂窝图分布(呈现靠近原值多,远离原值少且两端远离程度和数量相似的橄榄型分布)的值?
- 一个字典以表中某列的值为键,如何通过所给字典的键值对应关系,为该表填出一列新值?
- 如何为散点图按类别循环上色?
- 如何为散点图绘制注释